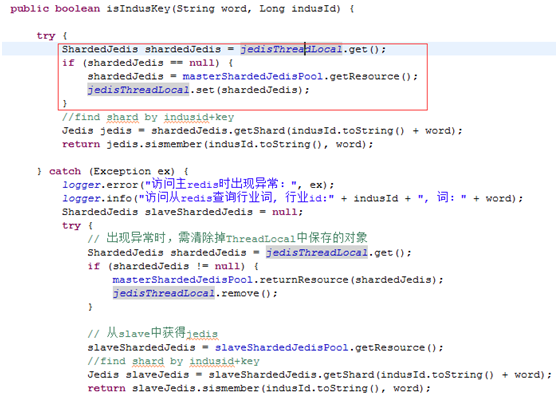
hadoop-yarn中ResourceManager的服务模块
Yarn简述
Hadoop2.0引入了yarn(Yet Another Resource Negotiator)资源管理框架。1.0中的MapReduce计算框架变为运行在yarn上的一种application。
Yarn依然采用了master/slave结构,master是ResourceManager,负责整个集群的资源管理和调度,并且支持HA,slave是NodeManager,负责管理各子节点上的资源和任务。每个MapReduce作业提交给ResourceManager并被接受后,ResourceManager会通知某个NodeManager启动一个ApplicationMaster管理此作业的生命周期。
ResourceManager中的模块划分
Yarn中的大多数服务都是带状态的service实现,并通过事件驱动机制实现服务的状态转换和服务之间的交互。ResourceManager是yarn的核心组件,与NodeManager、ApplicationMaster、Client都有交互,提供了非常多的功能,下面基于hadoop2.7版本的实现,梳理一下ResourceManager中的重要service组件及其功能。
ResourceManager中按功能划分的service模块如下图所示。
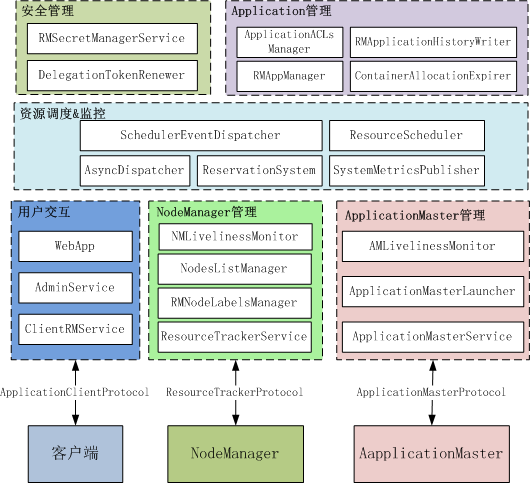
ResourceManager中核心模块主要包括客户端交互模块、NodeManager管理模块、ApplicationMaster管理模块、Application管理模块、安全管理模块、以及资源管理模块(调度、预留)等。
各模块中的服务介绍
客户端交互模块:
-
AdminService
- 管理员可通过此接口管理集群,如更新节点、更新ACL、更新队列等。内部有个EmbeddedElectorService,如果RM启用了自动HA,则通过这个service做leader election。
-
ClientRMService
- 负责为客户端提供服务,是ApplicationClientProtocol协议的服务端。负责处理来自客户端的RPC请求,包括提交app、查询app运行状态、终止app等。
-
Webapp
- 提供web页面服务,展示集群状态和资源使用情况。
NodeManager管理模块
-
NMLivelinessMonitor
- 用于监控NM是否存活,若NM在一定时间内(默认10分钟)未上报心跳,则认为其挂了。
-
NodesListManager
- 负责维护节点列表,并动态加载白名单(yarn.resourcemanager.nodes.include-path)和黑名单(yarn.resourcemanager.nodes.exlude-path)节点。
-
RMNodeLabelsManager
- 负责节点的标签管理。
-
ResourceTrackerService
- 负责与NodeManager通信,处理来自NodeManager的请求,包括注册NodeManager和节点心跳两种。接口定义在ResourceTracker中。
ApplicationMaster管理模块
-
AMLivelinessMonitor:两个实例
- 用于监控ApplicationMaster是否正常,如果在指定时间内(默认10分钟)未收到AM的心跳,则认为其死掉了。
-
ApplicationMasterLauncher
- 负责通知某个NodeManager启动或销毁ApplicationMaster。在app请求被接受后,与某个NodeManager通信,告知其为此app启动相应的ApplicationMaster。若app运行结束或被kill,则通知app所在NodeManager销毁ApplicationMaster。其内部也维护了一个阻塞队列,并有一个后台线程异步处理提交进来的启动ApplicationMaster的请求。
-
ApplicationMasterService
- 负责与ApplicationMaster通信,是ApplicationMasterProtocol协议的服务端,ApplicationMaster在NodeManager上启动后通过此协议向ResourceManager注册自己,运行过程中向ResourceManager发送心跳,以及app运行结束后告知RM自己所在的container可以被释放了。
Application管理模块
-
RMAppManager
- ResourceManager接受客户端提交的app后,会通过RMAppManager来触发启动app的事件RMAppEventType.START,具体启动app的工作由RMAppImpl实现。
-
ApplicationACLsManager
- 负责app权限控制,包括查看和修改权限。
-
ContainerAllocationExpirer
- 用于监听NodeManager上是否正常启动了分配给ApplicationMaster的container,若在指定时间未启动(默认10分钟),ResourceManager会强制回收该container。
-
RMApplicationHistoryWriter
- 负责异步持久化Application运行中的相关日志,主要是Container、Application、ApplicationAttempt在启动和结束时的日志信息。
安全管理模块
- RMSecretManagerService
- 负责管理各种通信密钥,包括:
- RM与NM通信的NMTokenSecretManagerInRM
- RM与container通信的RMContainerTokenSecretManager
- 客户端与AM通信的ClientToAMTokenSecretManagerInRM
- AM与RM通信的AMRMTokenSecretManager
- DelegationTokenRenewer
- 启用了安全时,负责定时更新认证token。
- 负责管理各种通信密钥,包括:
资源管理模块
-
ResourceScheduler
- 资源调度器,可通过yarn.resourcemanager.scheduler.class指定,ResourceManager默认使用的是org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler。
-
SchedulerEventDispatcher
- 用于处理SchedulerEventType类型的事件,其内部维护了一个存储SchedulerEvent的阻塞队列,并由一个后台线程从队列中取出资源请求事件,再调用ResourceScheduler进行处理。
-
ReservationSystem
- 资源预留系统,对应的实现有CapacityReservationSystem和FairReservationSystem。
此外,SystemMetricsPublisher负责发布RM的系统统计信息。AsyncDispatcher是中央事件处理分发器,ResourceManager启动时,通过它绑定了几种类型的事件的处理器,包括SchedulerEventType、RMAppEventType、ApplicationAttempt、RMAppAttemptEventType、RMNodeEventType、RMAppManagerEventType、AMLaunchEventType等。
上述各service在ResourceManager中的启动顺序为:
-
AsyncDispatcher
-
AdminService
-
RMActiveServices:是个CompositeService(即service列表,ResourceManager本身就是一个CompositeService),用于管理ResourceManager中的“活动”服务(必须在active的ResourceManager上启动的服务,启用HA时,备份ResourceManager上不启动这些服务),包括以下(按启动顺序):
-
RMSecretManagerService
-
ContainerAllocationExpirer
-
AMLivelinessMonitor
-
RMNodeLabelsManager
-
RMApplicationHistoryWriter
-
SystemMetricsPublisher
-
NodesListManager
-
ResourceScheduler
-
SchedulerEventDispatcher
-
NMLivelinessMonitor
-
ResourceTrackerService
-
ApplicationMasterService
-
ClientRMService
-
ApplicationMasterLauncher
-
DelegationTokenRenewer
-