简介
提交进入Storm运行的topology实际上是一个有向无环图(DAG),其中的节点是由spout和bolt组成,边则可以理解为消息从一个节点到传输到另一个节点的过程。对于spout产生的tuple,只有在topology上处理完毕后,才认为这个tuple被storm可靠处理。
Storm提供了可靠处理消息(storm中的通用名叫tuple)的框架,我们在写一个topology程序时,若需要保证spout产生的消息的可靠处理,需要做到两点:
第一是spout/bolt每生成一个新的tuple都告诉storm一下(其中spout发出的tuple有个id叫rootId),从而让storm能够追踪rootId和每个衍生tuple的处理状态。
第二是每个tuple被下游bolt处理完毕后,无论处理成功或失败,也再告诉storm一下,从而让storm知道是否需要spout重新发送rootId。
做了这两件事,storm就能知道这个tuple是否被处理完毕。如果是处理成功了的,就说明最初从spout发出的tuple(rootId)已在topology中处理完毕,无需spout重新发送。如果是处理失败的,storm则会告知spout重新发送rootId这个tuple。
在程序中实现消息可靠处理
那在写一个topology时,我们该如何做上面提到的两件事呢?
Storm提供了BaseRichBolt抽象类(实现了IRichBolt接口),一个示例bolt如下:
这段代码就做了这两件事,一是输出新的tuple并告知storm,二是对当前tuple t处理完毕后,告知storm。
对于第一件事,这里要注意的是,在BaseRichBolt中输出一个新的tuple(示例中是word)时,必须指定其锚点(即当前bolt正在处理的tuple),因为输出新的tuple会继续被下游bolt处理,这个锚点tuple和下游tuple之间的路径就是DAG的一条边。如果不指定锚点,则可以理解为storm不知道这条边的存在,也就不会对新输出的tuple进行跟踪了。
如果我们确实不需要保证消息的可靠处理,则使用以下方式输出新tuple即可。
|
|
另外,一个tuple的锚点tuple可以有多个,比如如下代码,新输出的tuple的锚点就是tuple1和tuple2。
|
|
对于第二件事,通过调用OutputCollector的ack或fail方法,即可告知storm当前tuple的处理结果。比如,假设我们在bolt中做一些操作的时候出现异常(比如访问redis、DB、hdfs等),可以调fail方法快速重放rootId,避免等到storm判断这个tuple处理超时后才重放。
更简便的方式
很明显,以上方式有几个弊端:
输出新tuple和对tuple的ack/fail操作需要我们自己维护,代价很高,容易遗忘。
storm是在内存中维护每个tuple的处理状态,如果只对tuple进行锚点标记但处理完毕后忘记ack/fail,在tuple量非常大时,有内存溢出的风险。
鉴于此,storm提供了BaseBasicBolt抽象类(实现了IBasicBolt接口)来帮助我们实现对每个tuple的锚点标记和ack/fail。
前面的例子可改写如下:
|
|
可见,在代码中,我们只需要关心bolt的处理逻辑即可,至于标记锚点和ack/fail,均不用关心。
细究一下storm框架对IBasicBolt的处理可知,在创建topology时,IBasicBolt是被封装在BasicBoltExecutor类(实现了IRichBolt接口)中处理的。
构建topology时的setBolt方法:

原理&示例
刚刚提到对每个topology,storm都在内存中维护其tuple的处理状态,那么对于一个大规模集群,storm是如何高效的维护大量tuple的处理状态的呢?
其实,topology在运行时,内部有一组特殊的任务叫acker,专门用来做tuple的ack/fail。当一个root tuple(spout输出的tuple)在DAG中处理完毕后,acker会向产生该tuple的spout发送消息来ack这个tuple。
我们可通过参数Config.TOPOLOGY_ACKER_EXECUTORS指定topology中的acker任务的数量,默认是与topology中的worker数相同,在处理大量消息的场景下,可以通过此参数增加topology的acker任务数,以提高对message做ack/fail的效率。
storm通过给每个tuple设置一个全局唯一id,并在输出tuple和tuple处理完毕时收集tuple的id,并进行异或运算,巧妙的实现tuple状态的维护。先看下图示例:
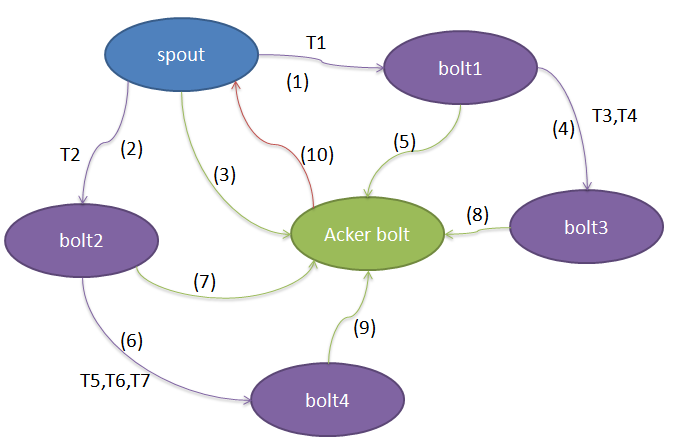
在这个topology其中包含一个spout,3个bolt和一个acker bolt,紫色线表示tuple的流向,绿色线表示每个bolt处理完tuple后的ack/fail调用,红色线表示acker回调spout的ack/fail方法来标记root tuple处理完毕。
以下是storm的ack框架对tuple的处理状态维护过程说明:
第(1)(2)步,spout发送T1到bolt1,发送T2到bolt2,T1和T2具有相同的内容(可以认为都把spout的输出作为自己的输入)。每条消息都会有一个全局唯一id,T1的锚点为
第(3)步,spout发送完毕T1、T2后,在acker中注册一条记录rootId=T1^T2。
第(4)(5)步,bolt1收到T1处理完毕后对T1进行ack并发送T3,T4到bolt3,所以在acker中注册T1,T3,T4,acker中的跟踪项变为rootId=T1^T2^T1^T3^T4=T2^T3^T4
第(6)(7)步,bolt2收到T2处理完毕后对T2进行ack并发送T5,T6,T7到bolt4,所以在acker中注册T2,T5,T6,T7,acker中的跟踪项变为rootId=T2^T3^T4^T2^T5^T6^T7=T3^T4^T5^T6^T7
第(8)步,bolt3收到T3,T4处理完毕后对T3,T4进行ack,没有输出新的tuple,所以在acker中注册T3,T4,acker中的跟踪项变为rootId=T3^T4^T5^T6^T7^T3^T4=T5^T6^T7
第(9)步,bolt4收到T5,T6,T7处理完毕后对T5,T6,T7进行ack,没有输出新的tuple,所以在acker中注册T5,T6,T7,acker中的跟踪项变为rootId=T5^T6^T7^T5^T6^T7=0
第(10)步,acker bolt发现rootId对应的追踪值为0,说明该rootId对应的源消息以及衍生出来的所有消息(bolt1,bolt2新输出的消息)都被成功处理完毕。于是acker bolt会回调spout的ack方法,标识消息rootId已被topology处理成功。